技术沙龙第五期
大勇:
今天要分享的是:云平台中的HPA(horizontal pod autoscalers)水平自动伸缩。
大勇:
虽然通常我们可以部署Deployment时设置pod 的数量。 但是这样设置不够灵活,在不同的运行环境,会导致资源的浪费,而随着吞吐量的上升,又需要不同的设置。
大勇:
HPA 即通过检测pod CPU的负载,解决deployment里某pod负载太重,动态伸缩pod的数量来负载均衡。
大勇:
大勇:
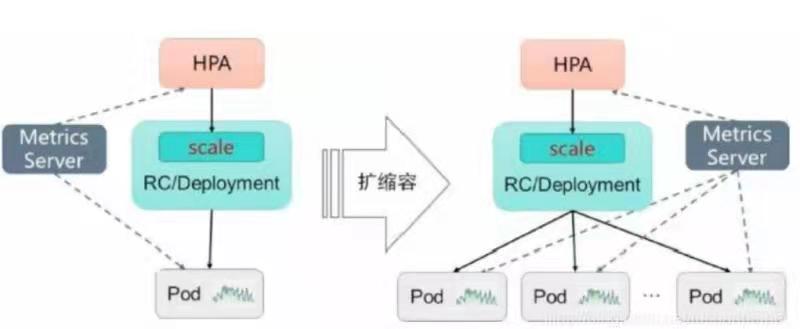
HPA可以检测pod cpu的使用情况,通知deployment增加或者减少所管理pod副本的数量。
大勇:
1、假如已经部署好了一个工作负载,deployment/kms. 现在需要配置HPA。设置kms的pod数量最小为2,最大为10 执行命令:kubectl autoscale deployment kms --min=2 --max=10
大勇:
当我们手动强行设置pod数为1时,kms的pod数量会马上删除一个,然后又重新创建一个新的pod,始终维持到最小数量2
大勇:
从步骤1来看,只是 为POD 限定了一个可设置的范围,也没多神奇的地方。
大勇:
步骤2 将进一步根据POD 负载指标,来设置自动扩容策略
大勇:
假如POD 的CUP 利用率超过80% 自动扩容
大勇:
则这样设置kms 的HPA kubectl autoscale deployment kms --min=2 --max=10 --cpu-percent=80
大勇:
这里设置了cpu-percent=80,表示pod的cpu利用率超过了百分之80会自动扩容,最小规格2个pod,每超过80%,再自动扩容,直到 pod最大数10.
大勇:
自动扩容,也不是无限扩容,也会参考当前集群总体资源来设置一个合理的区间阈值
大勇:
HPA 虽然能通过各自策略,实现POD的配置自动伸缩; 主要是仰仗SVC的强大的负载均衡
大勇:
k8s中svc有三种类型,分别为ClusterIP、NodePort、LoadBalancer;但是当SVC的类型是ClusterIP时,明显的POD端启动多个或者减少时,对服务的持续访问影响最小;而Deployment的部署方式,通常用在无状态部署,相当于访问每个POD 提供的功能效果是一样的。 即Deployment 部署的应用,最适合HPA自动扩容的方式。
大勇:
而当:SVC 是NodePort 对集群节点端口有依赖;SVC 是LoadBalancer 时对IP资源有要求; 或者通过SatefulSet(有状态) 方式部署的应用,每个POD 都有编号,pod的主机名会映射到DNS,相当于每个POD的都是不一样的。 则这些场景的云应用,采用HPA 自动扩容的方式又不太适用。
大勇:
好了,我今天的分享就到这了,主要是对POD 的自动化扩容提供了一种方法HPA,以及对它使用的场景进行了简单分析。 就我们当前的部署来看,大部分都是deployment 方式,还是能使用上的。