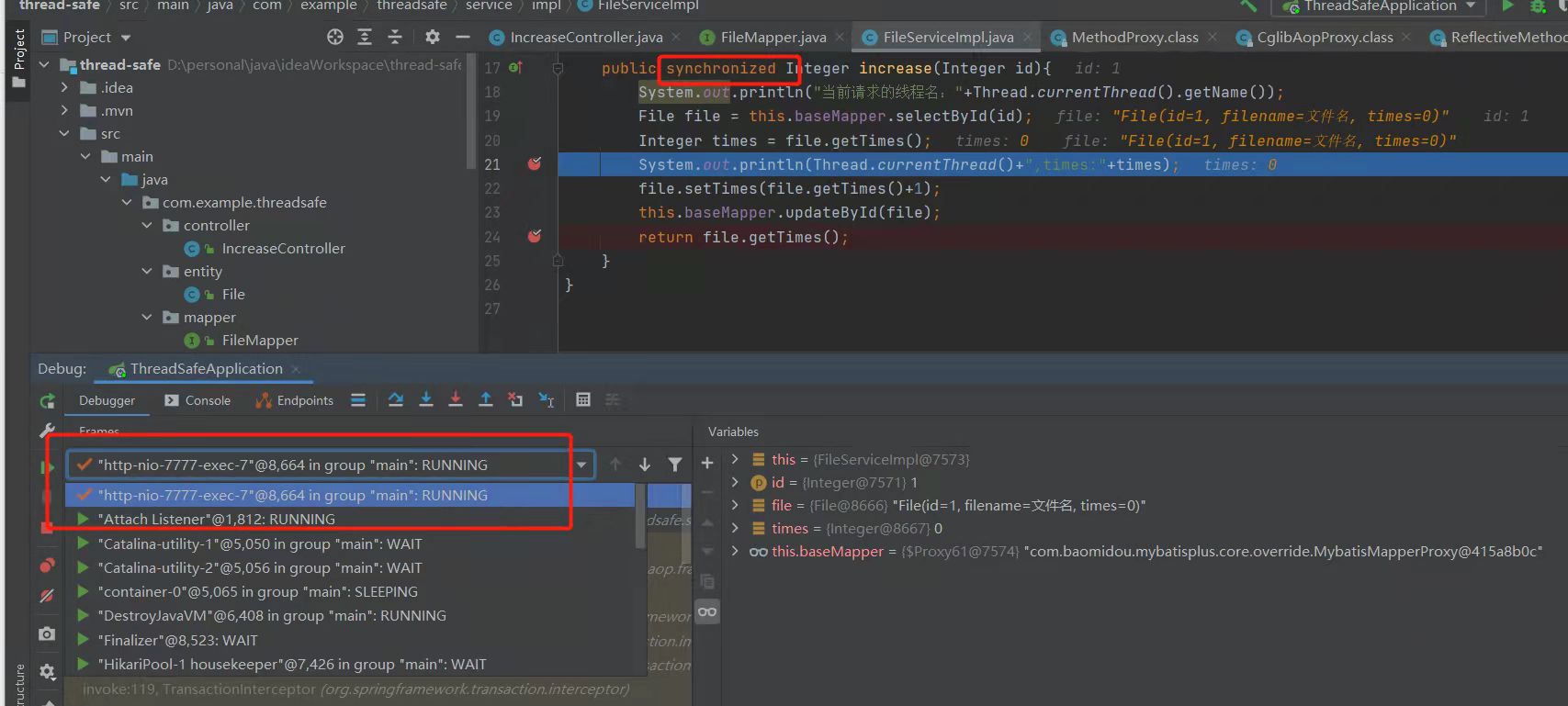
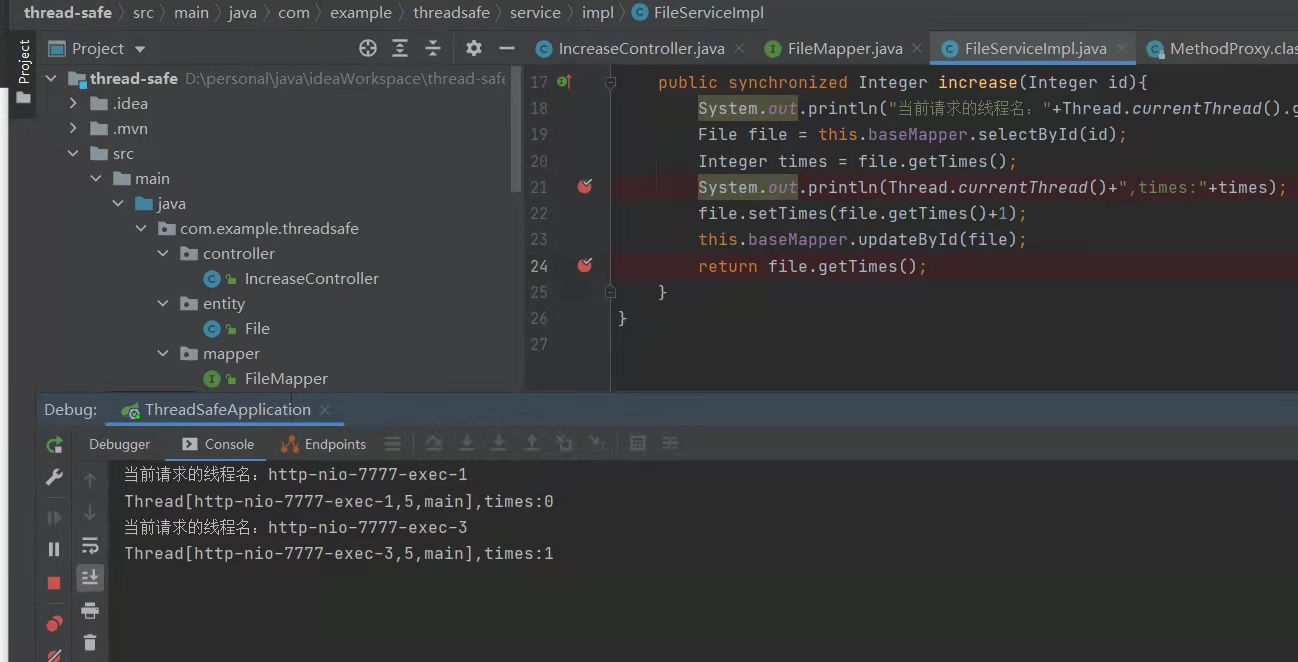
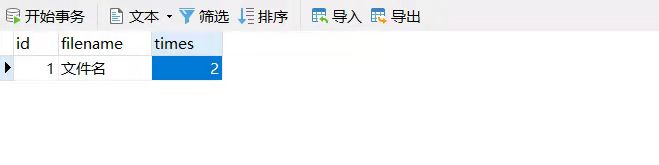
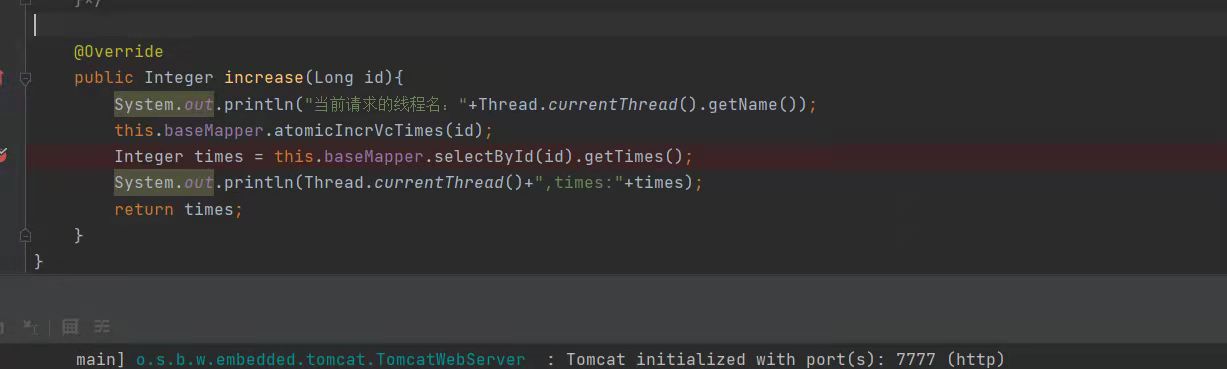
大勇:
今天分享与云端的流量入口、流量代理有关。
大勇:
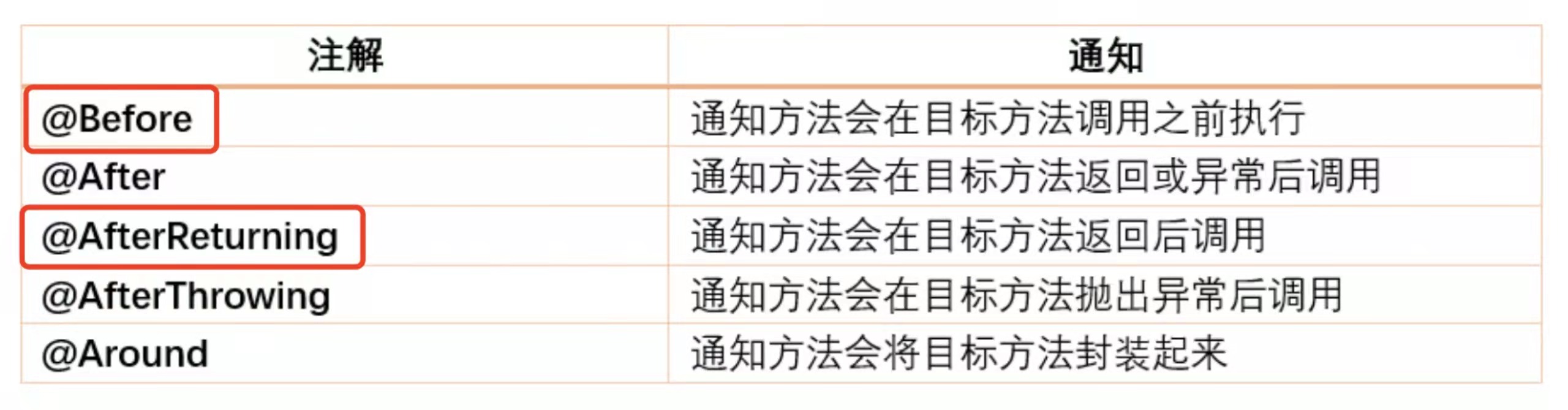
也看过一些云平台的部署架构、拓扑结构图之类的,发现很多,对流量代理、入口的界定不是很清晰。 有的把ingress 当成流量代理、有的认为是K8S service、有的认为是kube-proxy 等。 我这里再梳理下,其实以上都不是流量代理。
大勇:
ingress 是K8S 的一种原生资源(有别于CRUD的自定义资源),是描述具体的路由规则的。
大勇:
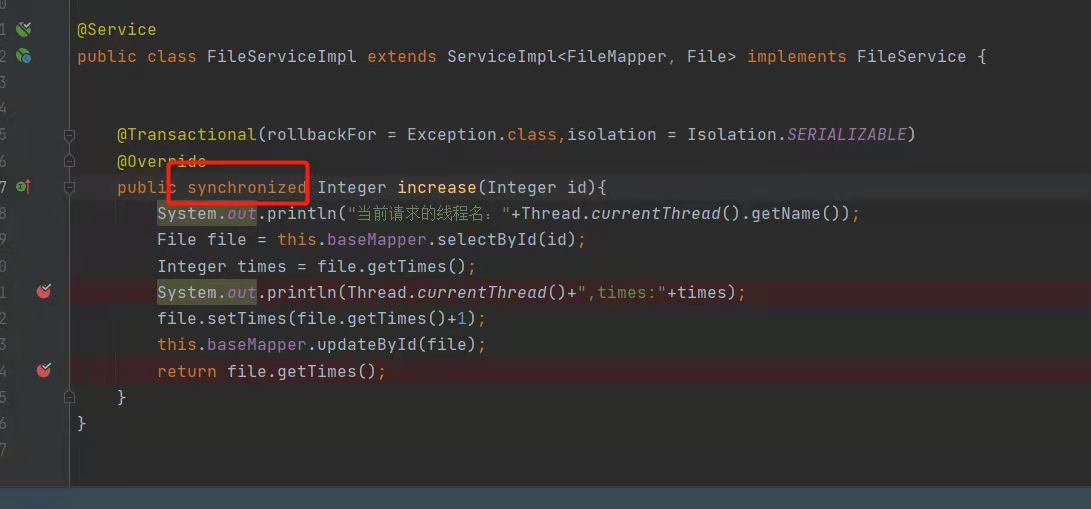
Ingress Controller 是才是流量的入口,是名副其实的流量代理,也可以称为边缘服务(集群内与集群外流量网关),纵向流量(有叫南北流量的说法), 一般是Nginx 、traefik和 Haproxy(较少使用)。
大勇:
Ingerss 描述了一个或者多个 域名的路由规则,以 ingress 资源的形式存在。
简单说: Ingress 描述路由规则。
大勇:
可以认为ingress 其实就是一个配置文件,而已,在你真正访问pod应用的时候 是没起任何作用的
大勇:
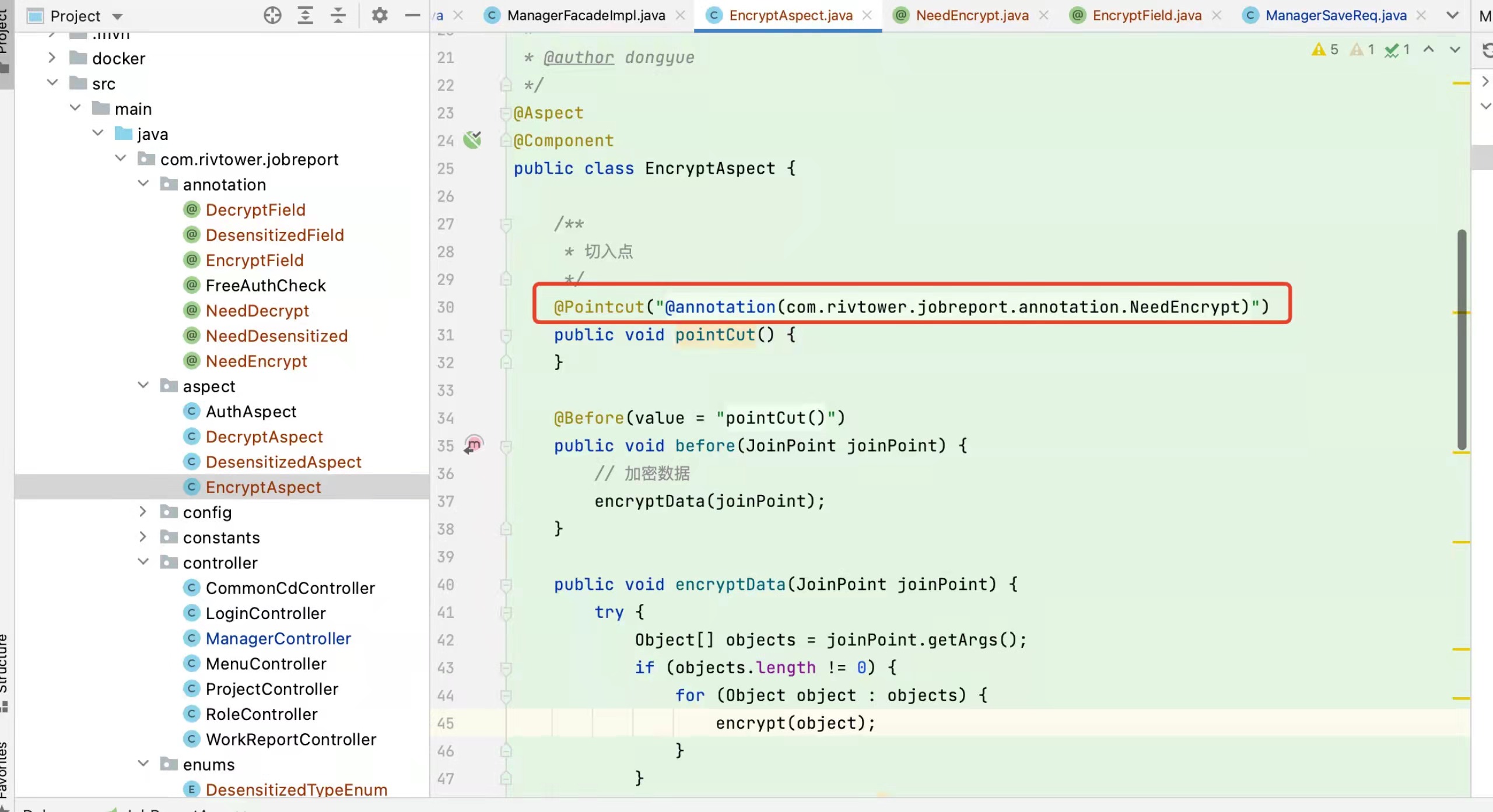
但是这个配置文件又不能删除, 这是因为Ingress Controller 实时实现规则。Ingress Controller 会监听 api server上的 /ingresses 资源 并实时生效。
大勇:
是Ingress Controller 是实时监听 api server 上ingresses ,如果没有了,会马上删除 自身的 反向代理配置 ,才让ingress 好像干掉了 就访问不了了。
大勇:
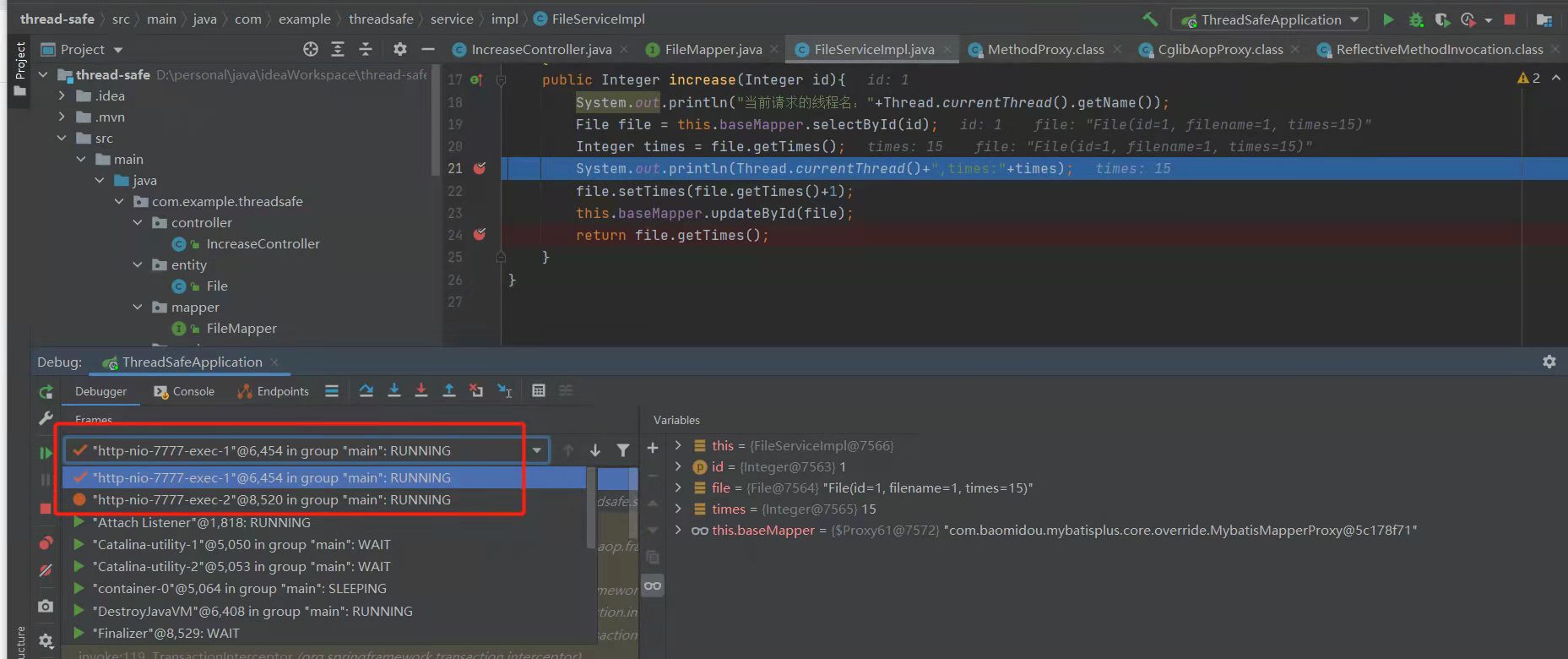
Ingress Controller 流量代理 自身的部署方式 以及服务类型 会决定了,整个K8S 的流量瓶颈,是每个节点的流量决定,还是整个集群所有的节点一起决定的。 这个先放后面,接下来讲,service与 kube-proxy 是否是流量代理的分析
大勇:
ingerss 与service的关系:
大勇:
ingress 在前,service在后, 前者不是流量代理, 顺利成章的会认为是后者,其实也不然。
大勇:
看K8S 对service的概念介绍:Service 概念
Kubernetes Service定义了这样一种抽象: Service是一种可以访问 Pod逻辑分组的策略, Service通常是通过 Label Selector访问 Pod组。
Service能够提供负载均衡的能力。
大勇:
service 有以下种类型:
大勇:
ClusterIp、NodePort、LoadBalancer(升级版nodeport)
大勇:
Service 也只仅仅是一种策略, 也不是应用每次被访问时,需要经过的组件,也不负载流量的转发。
大勇:
这里可能会有疑问,不负载流量转发,怎么又能实现这么多类型的服务,又怎么实现负载均衡的。
大勇:
这时候就该神奇的kube-proxy K8S组件闪亮登场了
大勇:
kube-proxy是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通信与负载均衡机制的重要组件; kube-proxy负责为Pod创建代理服务,从apiserver获取所有server信息,并根据server信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
在k8s中,提供相同服务的一组pod可以抽象成一个service,通过service提供的统一入口对外提供服务,每个service都有一个虚拟IP地址(VIP)和端口号供客户端访问。kube-proxy存在于各个node节点上,主要用于Service功能的实现,具体来说,就是实现集群内的客户端pod访问service,或者是集群外的主机通过NodePort等方式访问service。在当前版本的k8s中,kube-proxy默认使用的是iptables模式,通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降。
大勇:
kube-proxy当前实现了三种代理模式:userspace, iptables, ipvs。其中userspace mode是v1.0及之前版本的默认模式,从v1.1版本中开始增加了iptables mode,在v1.2版本中正式替代userspace模式成为默认模式。也就是说kubernetes在v1.2版本之前是默认模式, v1.2版本之后默认模式是iptables。
大勇:
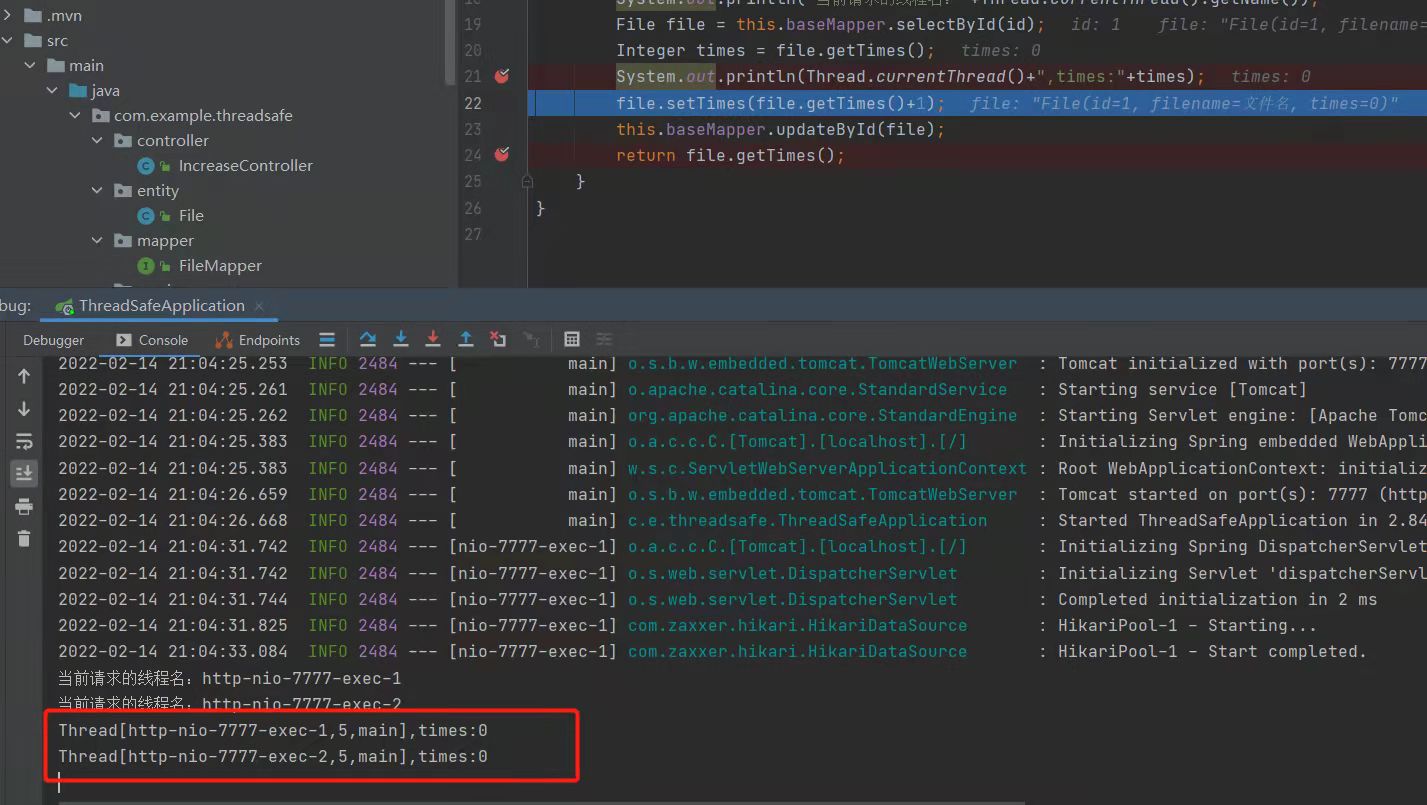
linux 分User space(用户空间)和 Kernel space(内核空间)。 在K8S 1.0 版本之前,kube-proxy 确实是流量代理
大勇:
每次的访问都是 从User space 到Kernel space 再到 User space 里的 kube-proxy
大勇:
显然这种方式会 因为K8S 底层组件的流量瓶颈,会影响整个上层应用生态
大勇:
使用userspace 的资源,比使用kernelspace的资源要昂贵的多, 这里引申一下, 能用TCP的场景,要比用HTTP的 节省资源。其他先不分析, 就工作层级来讲 TCP是工作在 kernelspace ,http是userspace 是应用层协议。
大勇:
第二个阶段,iptables mode, 该模式完全利用内核iptables来实现service的代理和LB, 这是K8s在v1.2及之后版本默认模式
大勇:
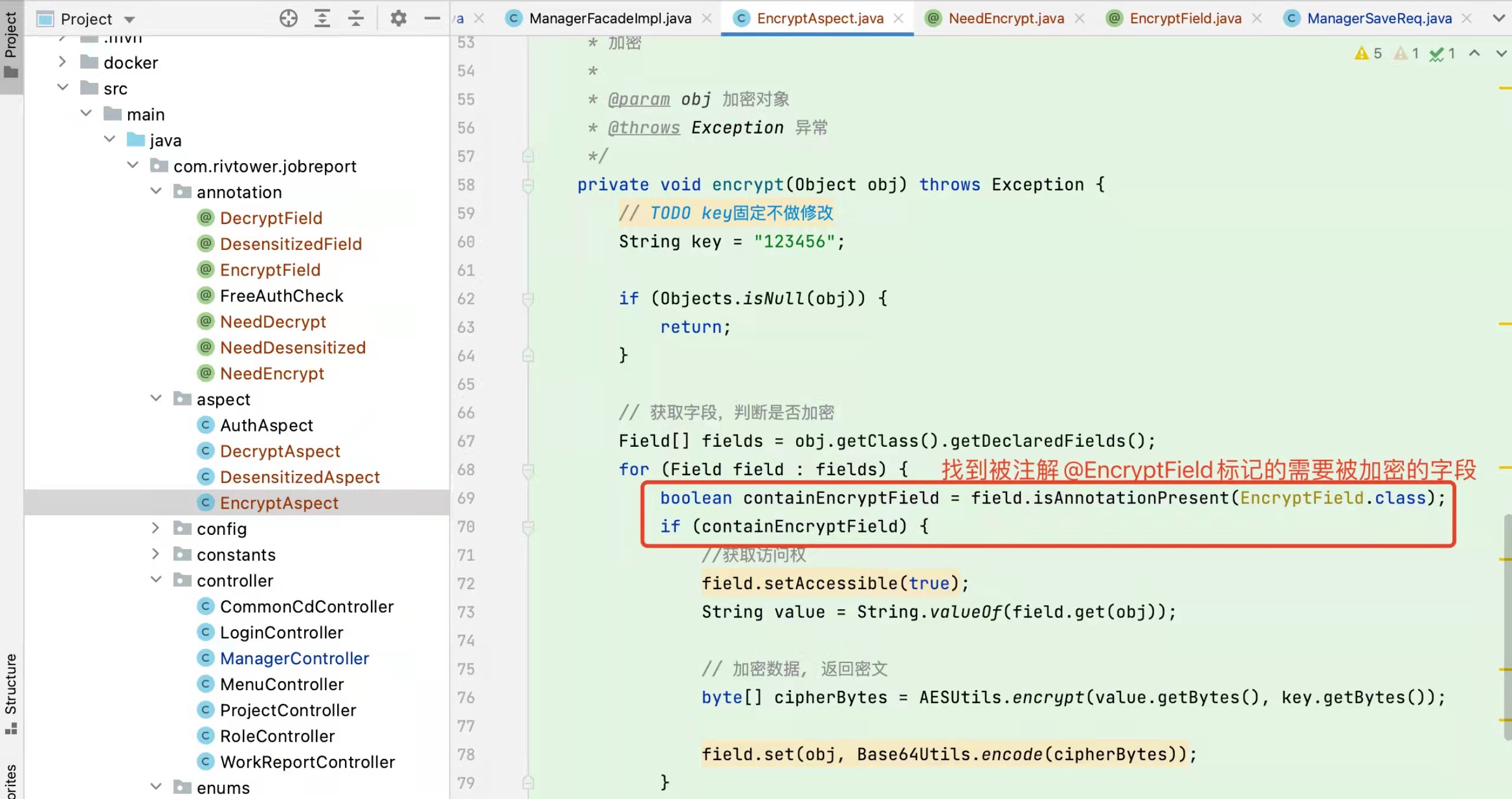
kube-proxy 在第二阶段 使用iptables mode 时,已经部署流量代理了,这些都交给 节点机器的iptables 路由表 来流量转换了, 而kube-proxy 只需要从api server 拿到service的策略配置,来实时维护好iptables 即可
大勇:
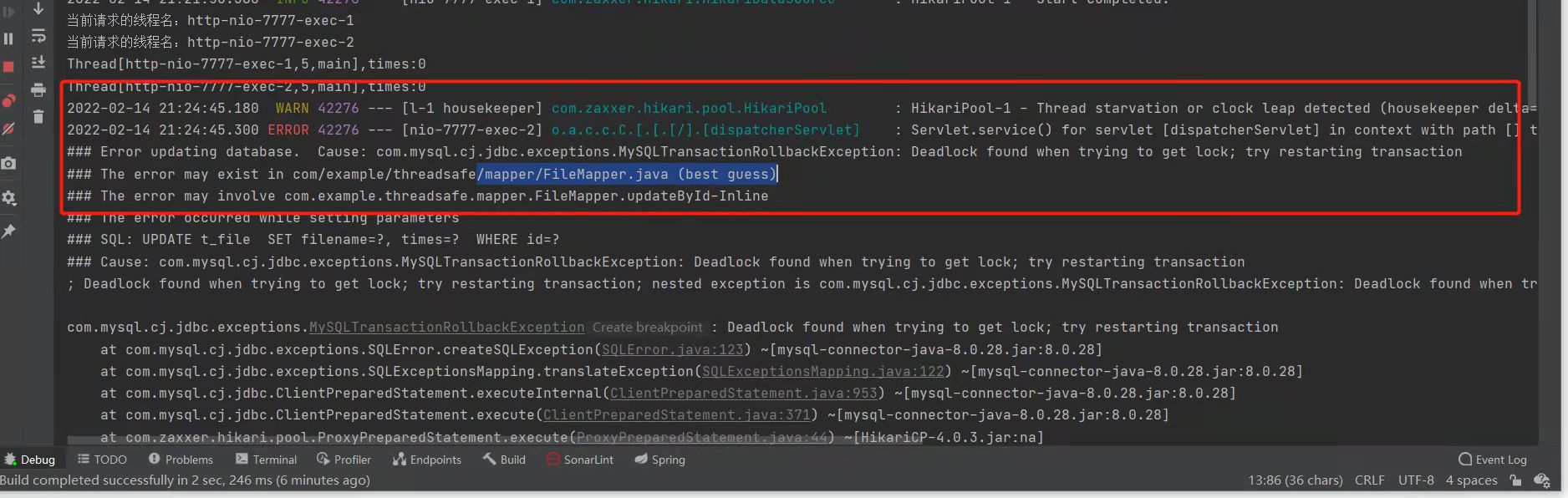
第二阶段,随着服务越来越多,维护Node上的iptables rules将会非常庞大,性能还会再打折扣
大勇:
故迎来了 第三阶段ipvs mode. 当下 一般的云都是这种模式
大勇:
在kubernetes 1.8以上的版本中,对于kube-proxy组件增加了除iptables模式和用户模式之外还支持ipvs模式。kube-proxy ipvs 是基于 NAT 实现的,通过ipvs的NAT模式,对访问k8s service的请求进行虚IP到POD IP的转发。
大勇:
kubedns/coredns 这个就是K8S的 dns服务器而已,不是流量代理,只提供了一个服务名、主机名等的DNS解析
大勇:
kube-proxy 经过以上阶段,也不是流量代理了,不会是应用访问的流量影响者
大勇:
综合以上分析,现在来看,流量控制代理瓶颈,不会出现在 K8S的service
大勇:
kube-proxy
大勇:
只有可能出现在 ingress-controller
大勇:
实际k8s 官方也提供了 ingress-controller的实现,只是也不太好用,
大勇:
现在基本都用 Nginx 、traefik、Haproxy
大勇:
来说下Nginx 吧, 早期版本部署是通过 DaemonSet 的方式
大勇:
这种方式就是每个节点启用一个 nginx代理
大勇:
但是会把当前节点机器的 80、443 端口占用掉
大勇:
因为Nginx 自身的 service 的暴露类型是 采用的 hostport 方式 类似与nodeprot 但是没负载均衡,就是只能用POD所在的节点机器IP 访问到
大勇:
好在是 DaemonSet方式,反正每个机器都有,用每个节点的IP 都能访问到nginx服务,然后反向代理到 应用的服务
大勇:
后面流量网关也进行了部署升级,先看下华为云的把:
大勇:
可以看到 不用DaemonSet,不用每台都启了, 启动几个pod就行, 自身的 service 也通过LoadBalancer 类型暴露了
大勇:
LoadBalancer 类型是需要负载均衡器来支持了,这种类型,如果采用类似BGP模式,理论上相当于 K8S集群每个节点的都可以成为流量入口。 相当于ingress-controller 作为流量入口,流量网关,它理论上可以做到,K8S的 所有节点都能充当入口。 以达到流量的最大化。
大勇:
今天的分析就到这了,梳理了一个论点,即:ingress-controller 才是流量代理,ingress、service、kube-proxy都不是,理论上可以做到流量的最大化,K8S 从机制上来看,没有流量瓶颈的桎梏。 要有也是 节点机器、其它方面的。