storageClasses: - # -- `StorageClass` Name. It is important. name: juicefs-sc # -- Default is `true` will create a new `StorageClass`. It will create `Secret` and `StorageClass` used by CSI Driver. enabled: true # -- Either `Delete` or `Retain`. Refer to [this document](https://juicefs.com/docs/csi/guide/resource-optimization#reclaim-policy) for more information. reclaimPolicy: Delete # -- Additional annotations for this `StorageClass`, e.g. make it default. # annotations: # storageclass.kubernetes.io/is-default-class: "true" backend: # -- The JuiceFS file system name name: "juicefs" # -- Connection URL for metadata engine (e.g. Redis), for community edition use only. Refer to [this document](https://juicefs.com/docs/community/databases_for_metadata) for more information. metaurl: "redis://:123456@redis-service.default:6379/1" # -- Object storage type, such as `s3`, `gs`, `oss`, for community edition use only. Refer to [this document](https://juicefs.com/docs/community/how_to_setup_object_storage) for the full supported list. storage: "minio" # -- Bucket URL, for community edition use only. Refer to [this document](https://juicefs.com/docs/community/how_to_setup_object_storage) to learn how to setup different object storage. bucket: "http://minio.zhujq:9000/juicefs" # -- JuiceFS managed token, for cloud service use only. Refer to [this document](https://juicefs.com/docs/cloud/acl) for more details. token: "" # -- Access key for object storage accessKey: "minio" # -- Secret key for object storage secretKey: "minio123"
let mock_client = TestClient::new(code); let retry_client = RetryClient::new(mock_client, Default::default()); let result = retry_client.test(1).await;
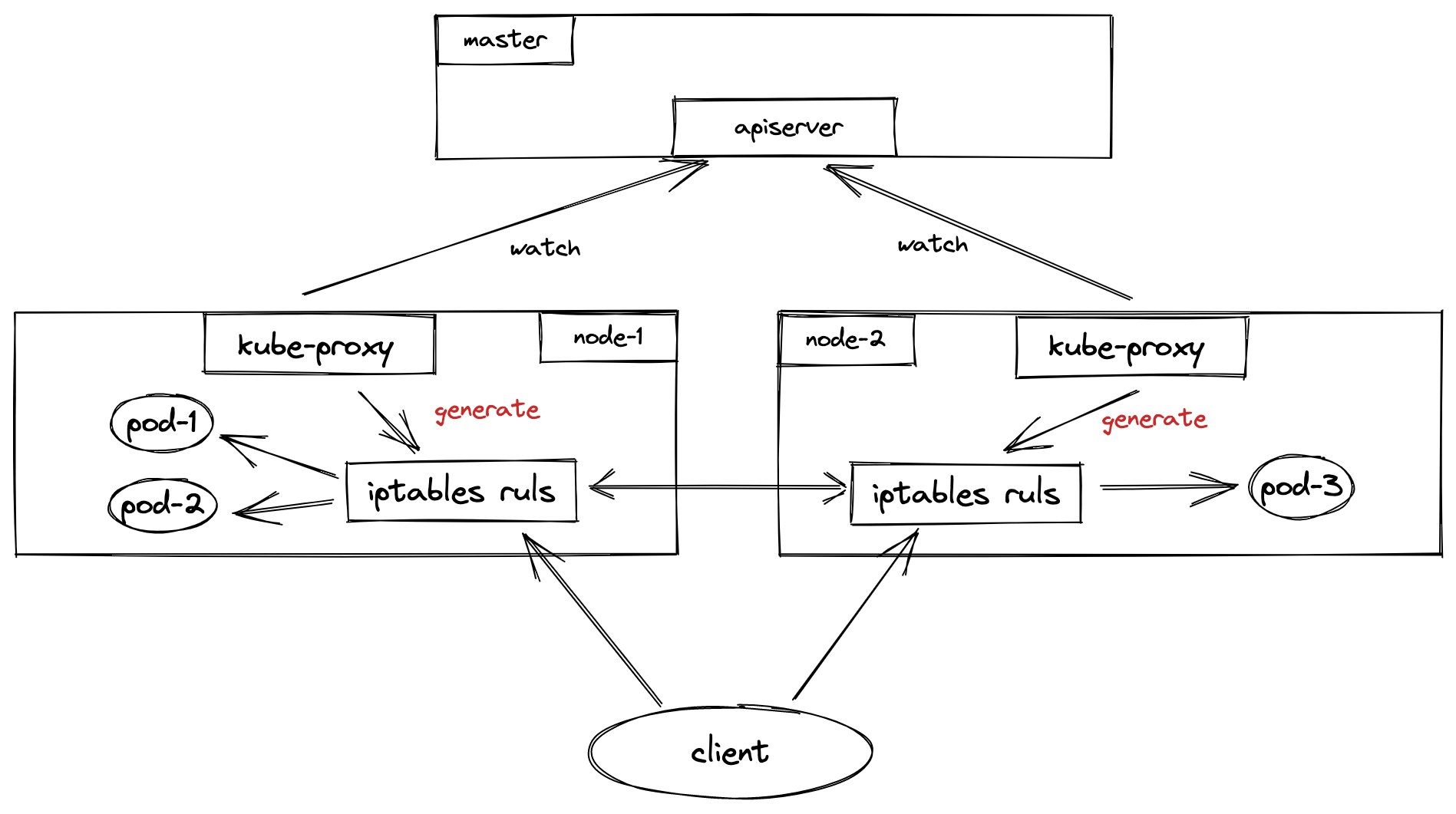
func(s *ProxyServer) Run() error { ... // 暴露/healthz接口 // Start up a healthz server if requested serveHealthz(s.HealthzServer, errCh) // 暴露指标信息 // Start up a metrics server if requested serveMetrics(s.MetricsBindAddress, s.ProxyMode, s.EnableProfiling, errCh) ... // 新建informerFactory // Make informers that filter out objects that want a non-default service proxy. informerFactory := informers.NewSharedInformerFactoryWithOptions(s.Client, s.ConfigSyncPeriod, informers.WithTweakListOptions(func(options *metav1.ListOptions) { options.LabelSelector = labelSelector.String() })) // kube-proxy主要watch了service和endpoint(或endpointSlices)资源的变动, // 当它们有变动时,对应节点上的iptables规则也会相相应地变动 // Create configs (i.e. Watches for Services and Endpoints or EndpointSlices) // Note: RegisterHandler() calls need to happen before creation of Sources because sources // only notify on changes, and the initial update (on process start) may be lost if no handlers // are registered yet. serviceConfig := config.NewServiceConfig(informerFactory.Core().V1().Services(), s.ConfigSyncPeriod) serviceConfig.RegisterEventHandler(s.Proxier) go serviceConfig.Run(wait.NeverStop) if endpointsHandler, ok := s.Proxier.(config.EndpointsHandler); ok && !s.UseEndpointSlices { endpointsConfig := config.NewEndpointsConfig(informerFactory.Core().V1().Endpoints(), s.ConfigSyncPeriod) endpointsConfig.RegisterEventHandler(endpointsHandler) go endpointsConfig.Run(wait.NeverStop) } else { endpointSliceConfig := config.NewEndpointSliceConfig(informerFactory.Discovery().V1().EndpointSlices(), s.ConfigSyncPeriod) endpointSliceConfig.RegisterEventHandler(s.Proxier) go endpointSliceConfig.Run(wait.NeverStop) } // 启动informer // This has to start after the calls to NewServiceConfig and NewEndpointsConfig because those // functions must configure their shared informer event handlers first. informerFactory.Start(wait.NeverStop) ... // Birth Cry after the birth is successful s.birthCry() // 进入定时循环 go s.Proxier.SyncLoop()
// Run waits for cache synced and invokes handlers after syncing. func(c *ServiceConfig) Run(stopCh <-chanstruct{}) { klog.InfoS("Starting service config controller") if !cache.WaitForNamedCacheSync("service config", stopCh, c.listerSynced) { return } for i := range c.eventHandlers { klog.V(3).InfoS("Calling handler.OnServiceSynced()") // 注册的事件动作执行相应的OnServiceSynced() c.eventHandlers[i].OnServiceSynced() } }
// OnServiceSynced is called once all the initial event handlers were // called and the state is fully propagated to local cache. func(proxier *Proxier) OnServiceSynced() { proxier.mu.Lock() proxier.servicesSynced = true proxier.setInitialized(proxier.endpointSlicesSynced) proxier.mu.Unlock() // Sync unconditionally - this is called once per lifetime. // 应用iptables rule到节点上 proxier.syncProxyRules() }
funccreateCloudProvider(cloudProvider string, externalCloudVolumePlugin string, cloudConfigFile string, allowUntaggedCloud bool, sharedInformers informers.SharedInformerFactory) (cloudprovider.Interface, ControllerLoopMode, error) { var cloud cloudprovider.Interface var loopMode ControllerLoopMode var err error if utilfeature.DefaultFeatureGate.Enabled(features.DisableCloudProviders) && cloudprovider.IsDeprecatedInternal(cloudProvider) { cloudprovider.DisableWarningForProvider(cloudProvider) returnnil, ExternalLoops, fmt.Errorf( "cloud provider %q was specified, but built-in cloud providers are disabled. Please set --cloud-provider=external and migrate to an external cloud provider", cloudProvider) } // 判断是否是external参数 if cloudprovider.IsExternal(cloudProvider) { loopMode = ExternalLoops if externalCloudVolumePlugin == "" { // externalCloudVolumePlugin is temporary until we split all cloud providers out. // So we just tell the caller that we need to run ExternalLoops without any cloud provider. returnnil, loopMode, nil } cloud, err = cloudprovider.InitCloudProvider(externalCloudVolumePlugin, cloudConfigFile) } else { // 输出弃用信息 cloudprovider.DeprecationWarningForProvider(cloudProvider) loopMode = IncludeCloudLoops // 初始化相应的云厂商provider cloud, err = cloudprovider.InitCloudProvider(cloudProvider, cloudConfigFile) } if err != nil { returnnil, loopMode, fmt.Errorf("cloud provider could not be initialized: %v", err) } if cloud != nil && !cloud.HasClusterID() { if allowUntaggedCloud { klog.Warning("detected a cluster without a ClusterID. A ClusterID will be required in the future. Please tag your cluster to avoid any future issues") } else { returnnil, loopMode, fmt.Errorf("no ClusterID Found. A ClusterID is required for the cloud provider to function properly. This check can be bypassed by setting the allow-untagged-cloud option") } } // 设置Informoer if informerUserCloud, ok := cloud.(cloudprovider.InformerUser); ok { informerUserCloud.SetInformers(sharedInformers) } return cloud, loopMode, err }
registerMetrics() s := &Controller{ cloud: cloud, knownHosts: []*v1.Node{}, kubeClient: kubeClient, clusterName: clusterName, cache: &serviceCache{serviceMap: make(map[string]*cachedService)}, eventBroadcaster: broadcaster, eventRecorder: recorder, nodeLister: nodeInformer.Lister(), nodeListerSynced: nodeInformer.Informer().HasSynced, queue: workqueue.NewNamedRateLimitingQueue(workqueue.NewItemExponentialFailureRateLimiter(minRetryDelay, maxRetryDelay), "service"), // nodeSyncCh has a size 1 buffer. Only one pending sync signal would be cached. nodeSyncCh: make(chaninterface{}, 1), }
serviceInformer.Informer().AddEventHandlerWithResyncPeriod( cache.ResourceEventHandlerFuncs{ // 添加事件回调函数 AddFunc: func(cur interface{}) { svc, ok := cur.(*v1.Service) // Check cleanup here can provide a remedy when controller failed to handle // changes before it exiting (e.g. crashing, restart, etc.). if ok && (wantsLoadBalancer(svc) || needsCleanup(svc)) { s.enqueueService(cur) } }, // 更新事件回调函数 UpdateFunc: func(old, cur interface{}) { oldSvc, ok1 := old.(*v1.Service) curSvc, ok2 := cur.(*v1.Service) if ok1 && ok2 && (s.needsUpdate(oldSvc, curSvc) || needsCleanup(curSvc)) { s.enqueueService(cur) } }, // No need to handle deletion event because the deletion would be handled by // the update path when the deletion timestamp is added. }, serviceSyncPeriod, ) s.serviceLister = serviceInformer.Lister() s.serviceListerSynced = serviceInformer.Informer().HasSynced
...
if err := s.init(); err != nil { returnnil, err }
return s, nil }
// LoadBalance类型 funcwantsLoadBalancer(service *v1.Service)bool { // if LoadBalancerClass is set, the user does not want the default cloud-provider Load Balancer return service.Spec.Type == v1.ServiceTypeLoadBalancer && service.Spec.LoadBalancerClass == nil }
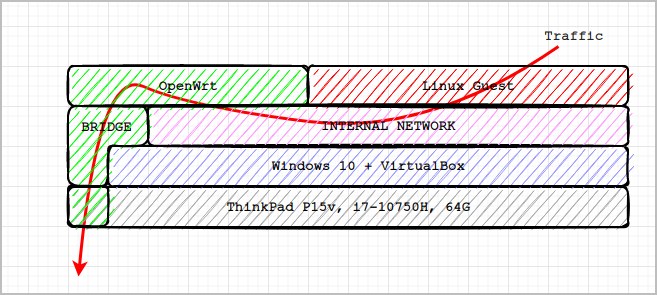
但是,随着办公平台的扩大,我们平时不得不以 Linux 系统为主要办公环境,但是有的时候会用到 Windows 系统,尤其是需要运行仅支持 Windows 平台的软件(例如 企业微信、钉钉、微信 等等)。我们尝试更换 Macbook,但并不能解决问题;两个笔记本,携带也不方便;通过 Wine 方案,仅能解决部分软件的运行问题,仍旧存在部分软件无法通过 Wine 来运行。
所以,我们尝试在虚拟机中运行操作系统,将我们的办公环境迁移到虚拟机。我们在宿主机中运行 Linux 操作系统,并在其中部署桌面虚拟化(例如 VirtualBox 等等),并在虚拟机中运行 Windows 操作系统。同时,借助虚拟机的 Guest Additions 组件,实现宿主机与虚拟机之间互操作(例如 文件共享、复制粘贴 等等)
+-------------------------------------------------+ | OpenWrt | Windows VM | Linux VM | ... | +-------------------------------------------------+ | LINUX + KVM + Storage | +-------------------------------------------------+ | LAPTOP | +-------------------------------------------------+
# kubectl apply -f test-resources.yaml ... Status: Conditions: Last Transition Time: 2022-04-01T09:51:50Z Message: Certificate is up to date and has not expired Observed Generation: 1 Reason: Ready Status: True Type: Ready Not After: 2022-06-30T09:51:50Z Not Before: 2022-04-01T09:51:50Z Renewal Time: 2022-05-31T09:51:50Z Revision: 1 ...